Table Recognition - From OCR to Deep Learning

Source: CascadeTabNet
{kind=link}
Discussing Evolution & Techniques on Table Recognition
- Introduction
- Traditional Method — OCR
- Adopting Deep Learning in Table Recognition
- DeepDeSRT from Microsoft
- What are the Future Directions?
- Reference
Imagine you need to digitalize the document image into a text file using Python / any other programming language you know. It might seem straightforward to use Optical Character Recognition (OCR) to convert images into text files, but what if the image contains tables, and you need to format the output as a CSV file?
Some would suggest using scanner tools (Adobe Acrobat Reader) or vendor solutions (Nanonets) to do the job, however, it’s costly (not open-source) and sometimes we might run into some legal and compliance issues. Wouldn’t it be nice if we have an open-source tool that can identify tables and extract formatted data? This blog will explore different techniques and investigate the feasibility of such tools.
Introduction
As more companies adopt digital transformation, the amount of data collected is dramatically increasing daily. One of the powerful ways to represent information is using tabular data, and they are everywhere in different raw documents, such as historical documents, scientific journals, receipts, and financial reports. Applying artificial intelligence to automate information extraction is critical to the whole digitalization process. Not only it can save time, but also allow accurate information retrieval, which could eventually be beneficial to different industries, including retail, journalism, catering, finance, and more.
Having an automatic tool sounds ideal and optimistic. However, there are a few common challenges in table recognition:
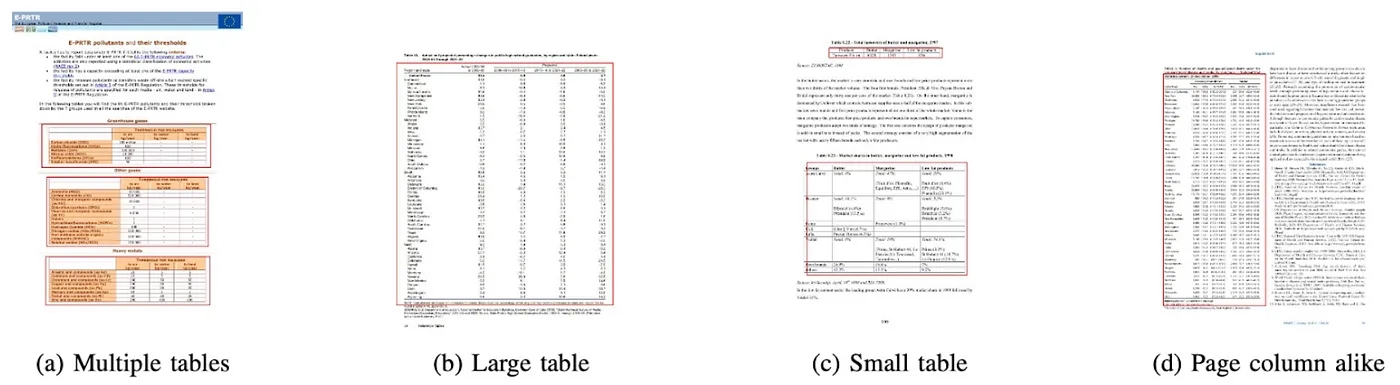
Source: Nanonets — Table Extraction Deep Learning
To cope with these challenges, computer scientists have used the traditional method, such as OCR, to identify word positions, extract texts, and understand document structure. With the advance of data science, deep learning has been introduced to solve this problem. Below, we will discuss what type of old-school method were people using to recognize the table from an image, how new technologies have helped the field, and what are the future directions and potential advancements.
Traditional Method — OCR
Early in the 1900s, people are trying to automate the process of converting images into text files. Emanuel Goldberg, a German scientist, created a device that could scan characters and translate them into standard telegraph code (early OCR). The concepts of Optical Character Recognition (OCR) are still useful nowadays to recognize and digitalize text information from an image.
How does the OCR works? Basically, it uses the techniques of pattern recognition and feature analysis. The former train the model with a large scale of characters with different variations and compare it with the testing data. Those with high similarity characters will return. While the latter considers the number of matching features (e.g. straight line, connected component, etc.).
Tesseract OCR

Source: Tesseract OCR Logo
{kind=link}
One of the famous open-source OCR software, Tesseract OCR¹, is originally developed by HP from 1984 to 2005 until Google own it in 2006. It supported 6 languages in 2007 and expanded to 100 languages in 2015. Other than converting images to text data, it also supports layout analysis and exporting to PDF format.
Typical Text Extraction
Before understanding how OCR can help extract information from the table. We first need to explore how Tesseract OCR can identify a character. Below shows a simple feature extraction from an identified potential character. It extracts the topological features, for example, the connection between each edge, and the direction of the topological feature. Similar to traditional machine learning, further classification methods (KNN, SVM) can be applied to classify the potential character to the corresponding label (in the example below, ‘R’).
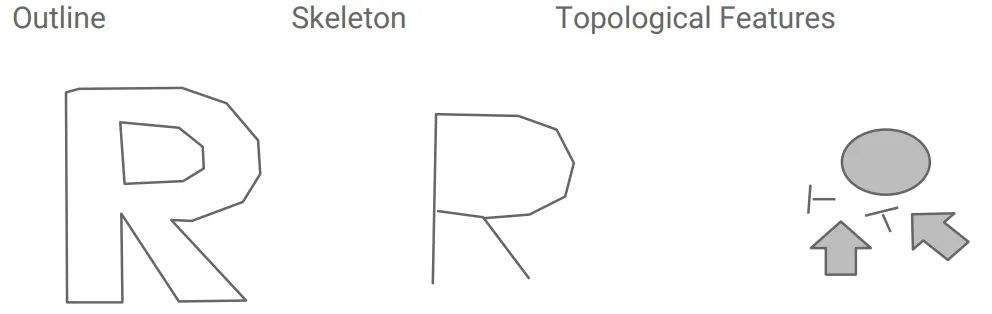
Source: Tesseract OCR — How to extract features from Outlines?
Apart from feature extraction from a character, Tesseract OCR also needs to handle word segmentation (separate between different characters). More details can be found in Tesseract’s presentation.
Tesseract’s Layout Analysis on Table Detection
As of 2014, Tesseract OCR is capable of analyzing document layouts. In this context, it is able to detect and identify several cells from the segmented blocks (potentially tables). The table detection algorithm follows the below steps:

Source: Tesseract OCR in Table Detection
Since the OCR method enables the software to recognize and extract the individual cells of the table, including the column and row headings, it is particularly helpful for extracting data from tables. This can be achieved by using rule-based table extraction. It is a set of pre-programmed rules to distinguish a column and row by a fixed size or separate a cell by its spacing. However, the major limitation is that this method is not flexible enough to handle all kinds of tables, especially for those with complex layouts. Originally, OCR is designed for text extraction rather than table recognition. But people use OCR before the application of deep learning.

Source: Sample OCR Recognized Image with Bounding Box
{kind=link}
Q: Can Deep Learning Come to the Rescue?
A: Short answer, yes!
A: Long answer follows …
Adopting Deep Learning in Table Recognition
With the advance of deep learning, it has emerged as a powerful technique for various computer vision tasks, involving table detection and recognition. The capability of deep learning models to learn complex, non-linear relationships between input and output data enable them suitable for information retrieval from tables, which are highly encouraged to handle a variety of complex table formats and layouts. They are able to recognize tables in both structured and unstructured documents and can extract data even when tables are not perfectly aligned or formatted.
Deep Learning Introduction & its Applications in Table Recognition
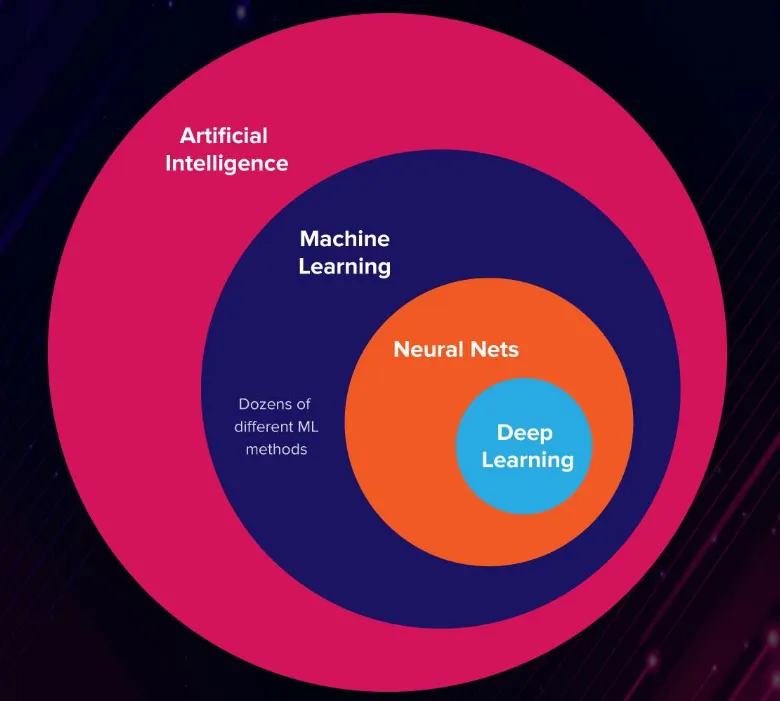
Source: ML vs DL
Deep learning is the subclass of AI and machine learning that utilizes neural networks (mimics the human brain) to study non-linear relationships between features and output labels.
Usually, we need to fit a large amount of labeled data and create a pre-trained model (ready-to-use ML model) for other uses without tedious and time-consuming model training. The ability to understand the high-level features and representation of the document features makes them fit in image recognition, speech generation, and video transformation. In the context of this blog, deep learning can be used to investigate the underlying layout and structure of the table.
Overview of Famous Neural Network Architecture for Table Recognition
There are several popular deep-learning architectures that are suitable for recognizing tables:
Convolutional neural networks (CNNs) are designed for image classification and could be trained to identify the general structure of the tables (e.g. columns and cells).
Recurrent neural networks (RNNs) are used for analyzing sequential data such as text extraction from tables.
Fully convolutional networks (FCNs) introduced the “encoder-decoder” architecture for achieving a high-level understanding of the data.
DeepDeSRT from Microsoft
Among all previous deep learning-based table recognition algorithms, we select one of the famous (51,666 downloads on December 2022 from Hugging Face), open-source, and high-accuracy achieving models called DeepDeSRT² developed by Microsoft Research. According to the research paper, this model achieved 0.968 and 0.914 F1-score on table detection and structure recognition tasks respectively, which is relatively high compared to other models like Fast RCNN.
DeepDeSRT Architecture
This model uses a transformer architecture to recognize and extract structured data from tables. The model accepts the document image as input and generates a descriptive structured representation of the table as output. The returned representation contains information describing the table’s layout, row and column boundaries, and the text content from each cell. In order to train the algorithm to detect and reliably extract this information, a large dataset of tables was used as training data.
The DeepDeSRT used a pre-trained model as the backbone to perform transfer learning, it is built on top of ResNet-18.
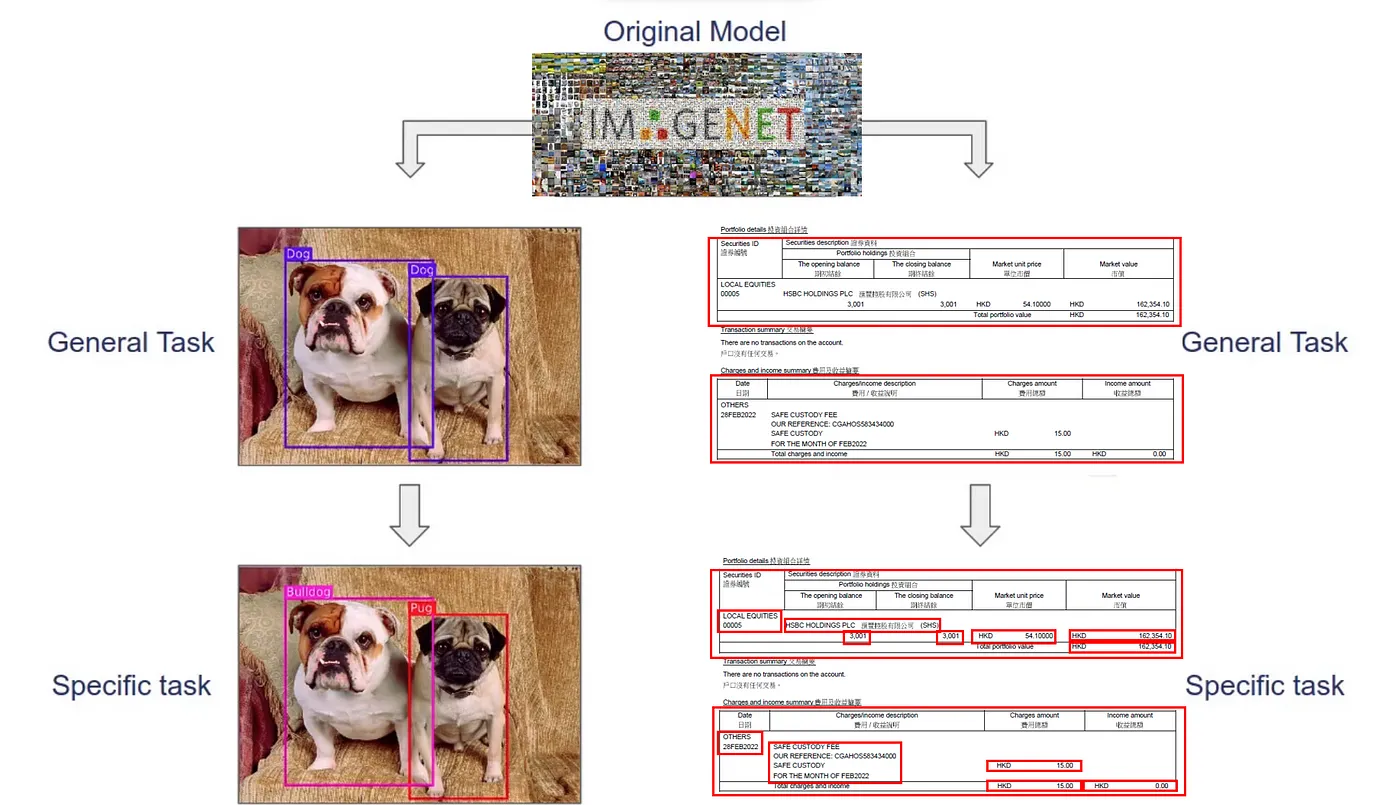
Source: Author, Imagenet icon
Transfer Learning is a machine learning technique that used the trained model as the starting point of the new task. For example, one pre-trained model called ResNet designed for object detection and image classification. We can use ResNet’s pre-trained weight for our new task (table recognition), which can save the time to fit the model from scratch.
Since the DeepDeSRT research paper is not publicly available, we will be using DEtection TRansformer (DETR) materials to explain similar neural network structures. CNN is used for feature extraction, while the transformed first encodes the image feature into a low-dimension vector and then passes it to the decoder to obtain the box prediction generated from the model. Finally, a bounding box returned to indicate how many and where are the objects spotted.

Source: DEtection TRansformer Underlying Structure
The transformer architecture is a type of neural network that is particularly well-suited for tasks involving sequential data, such as text. It uses self-attention mechanisms to weigh the importance of different parts of the input in order to make decisions about the structure and content of the table.

Source: API Demo From DETR

Source: DeepDeSRT failed cases
As we can observe above, although deep learning adoption can improve the accuracy and F1-score. However, there are still some exceptional cases that the deep learning-based failed to recognize.
What are the Future Directions?
Even with the help of deep learning, the algorithm still suffers from poor image quality and complex table structure. Incorporating transformer topologies into table recognition models, such as DETR (End-to-End Object Detection with Transformers), might be one area of emphasis. This could enhance the precision and effectiveness of table recognition systems.
Incorporating object identification metrics and creating more durable models that can handle a broader variety of table layouts and formats are two further interesting study areas. The performance of deep learning-based table identification algorithms on huge datasets, like PubTables-1M, might be another topic of interest. Additionally, combining deep learning with other AI methods like computer vision, natural language processing, and graph neural networks may result in brand-new approaches to the problem of table recognition.
Reference
Share on: